Resources
About Us
Synthetic Medical Data Generation Platforms Market by Data Type (Electronic Health Records Data), Technology, Deployment Mode (Cloud-Based, On-Premise, Hybrid), End User, and Geography — Global Forecast to 2036
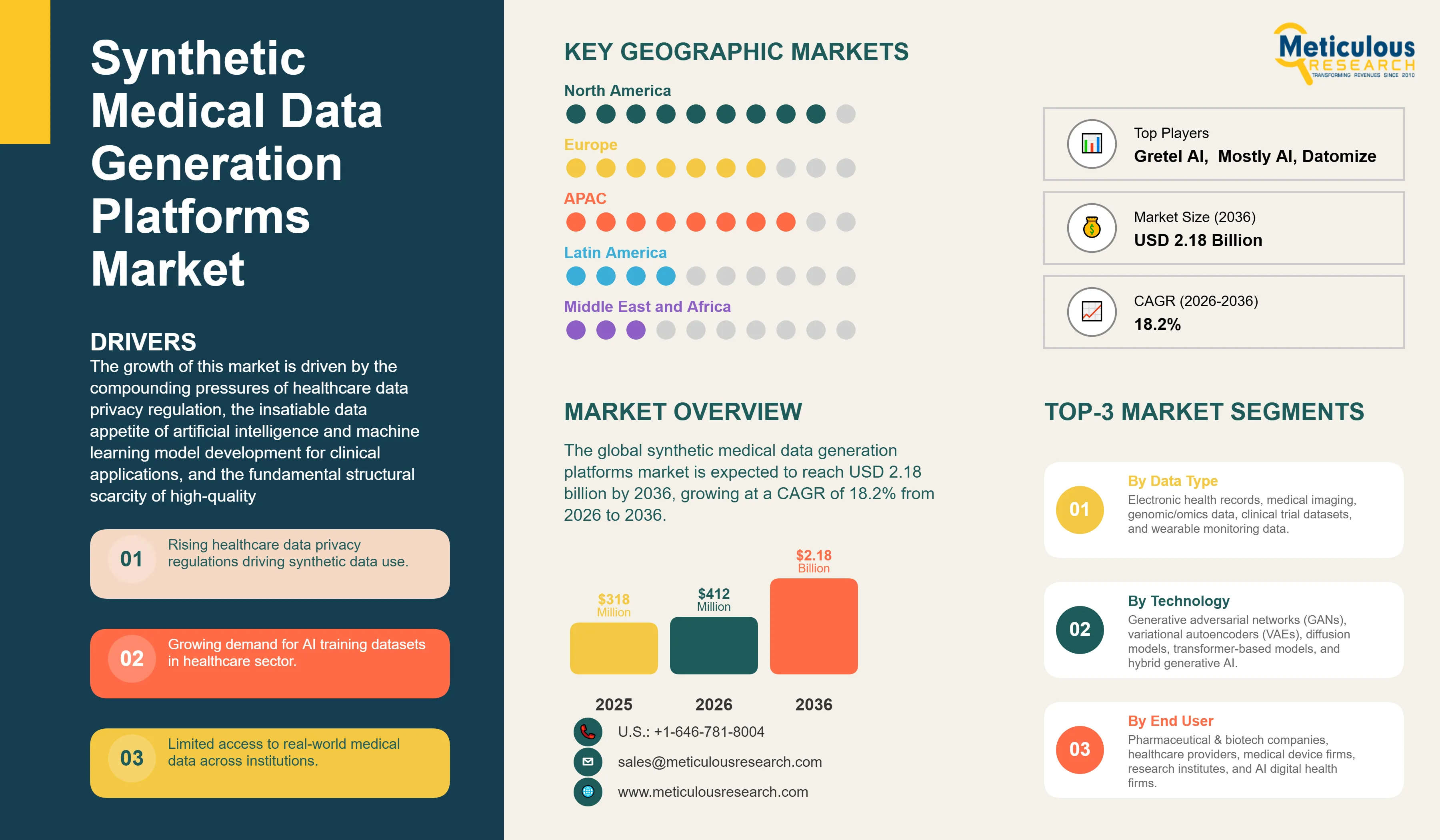
Report ID: MRHC - 1041846 Pages: 277 Mar-2026 Formats*: PDF Category: Healthcare Delivery: 24 to 72 Hours Download Free Sample ReportThe global synthetic medical data generation platforms market was valued at USD 318 million in 2025. This market is expected to reach USD 2.18 billion by 2036 from USD 412 million in 2026, growing at a CAGR of 18.2% from 2026 to 2036.
The growth of this market is driven by the compounding pressures of healthcare data privacy regulation, the insatiable data appetite of artificial intelligence and machine learning model development for clinical applications, and the fundamental structural scarcity of high-quality, properly labeled, demographically diverse real-world medical datasets that can be freely shared across organizational boundaries without triggering regulatory liability. Synthetic medical data generation platforms are software systems that use advanced generative artificial intelligence techniques — principally generative adversarial networks, variational autoencoders, diffusion models, and transformer-based large language and multimodal models — to produce artificial healthcare datasets that replicate the statistical properties, structural characteristics, and clinical patterns of real patient data while containing no actual patient information and therefore posing no re-identification risk under applicable privacy frameworks. These platforms generate synthetic versions of electronic health records, medical imaging datasets, genomic sequences, clinical trial datasets, and continuous monitoring data streams that can be freely shared with AI development teams, research collaborators, regulatory bodies, and commercial partners in contexts where sharing the underlying real patient data would be legally prohibited, technically restricted, or ethically problematic.
The synthetic medical data generation market addresses a paradox at the heart of healthcare AI development: the clinical AI systems that could most dramatically improve healthcare outcomes — diagnostic imaging algorithms, sepsis prediction models, drug response predictors, and rare disease classifiers — require training on the largest and most diverse patient datasets, yet the most sensitive and privacy-protected category of personal data in virtually every legal system is medical information. HIPAA in the United States, GDPR in Europe, and equivalent frameworks across Asia and Latin America impose strict access controls, data sharing agreements, and de-identification requirements on real patient data that create substantial barriers to the data aggregation and sharing that AI training requires. Synthetic data generation platforms resolve this tension by producing statistically equivalent artificial datasets that inherit the clinical utility of real patient data for AI training purposes while being legally and technically distinct from the real patient records from which the generative models learned.
Click here to: Get Free Sample Pages of this Report
Synthetic medical data generation represents one of the most technically sophisticated and commercially consequential applications of generative artificial intelligence to emerge from the broader AI revolution of the past decade. The technical problem that synthetic medical data platforms solve is deceptively straightforward in concept but extraordinarily challenging in practice: training a generative model to learn the complex statistical relationships, clinical coding conventions, temporal dependencies, and population-level distributional properties embedded in large real healthcare datasets well enough that the synthetic outputs it produces are statistically indistinguishable from real data for downstream AI model training and clinical research purposes — while simultaneously providing formal mathematical guarantees that the synthetic data cannot be reversed to reconstruct or re-identify any individual patient record.
The technical architecture of synthetic medical data generation platforms varies significantly across the different data modalities they address, reflecting the fundamentally different structural and statistical properties of structured EHR data, high-dimensional medical imaging, sequential genomic data, and time-series physiological monitoring data. For structured EHR data encompassing demographics, diagnoses, procedures, medications, laboratory results, and clinical notes, platforms including MDClone, Syntegra, and Mostly AI have implemented GAN-based and transformer-based architectures that learn to reproduce the correlational structure of patient records including the temporal sequencing of clinical events, the co-occurrence patterns of diagnoses and medications, and the demographic distributions of clinical variables across patient populations. For medical imaging data, platforms including Gretel AI, Hazy, and specialized radiology AI companies have developed GAN-based and diffusion model-based architectures capable of generating synthetic images that radiologists and pathologists cannot reliably distinguish from real patient images in blinded evaluation studies. For genomic and omics data, highly specialized platforms address the unique challenge of generating synthetic genome sequences that preserve population-level genetic diversity patterns and variant frequency distributions without reproducing any actual patient's genetic information.
The commercial ecosystem of the synthetic medical data generation market encompasses three distinct business model architectures. Pure-play synthetic data platform companies including MDClone, Syntegra, Gretel AI, Mostly AI, Hazy, YData, Datomize, and Betterdata offer dedicated synthetic data generation software as a cloud service or on-premise deployment, targeting healthcare organizations, pharmaceutical companies, and health AI developers as their primary customers. Healthcare data and analytics companies including IQVIA and HealthVerity are integrating synthetic data generation capabilities into broader real-world evidence and healthcare data analytics platform offerings, leveraging their established pharmaceutical industry relationships and large proprietary real-world data assets to provide synthetic data services as a premium complement to their core data products. Major technology platform companies including Google Health and Microsoft are developing synthetic healthcare data capabilities within their broader healthcare cloud and AI platform strategies, competing for enterprise healthcare and pharmaceutical company relationships through integrated platform offerings that combine synthetic data generation with AI model training infrastructure and deployment services.
The privacy-preservation framework that distinguishes synthetic data from conventional de-identification approaches is grounded in the concept of differential privacy — a formal mathematical framework that provides probabilistic guarantees about the maximum amount of information about any individual that can be inferred from the synthetic dataset, regardless of what auxiliary information an adversary might possess. Platforms that implement differential privacy guarantees at provable privacy budget levels provide healthcare organizations with a defensible technical and legal basis for sharing synthetic datasets without triggering HIPAA's covered entity or business associate obligations or GDPR's personal data restrictions, as the synthetic data by construction does not contain personal information as defined under these frameworks. The evolution of privacy-preservation technical standards and the developing body of regulatory guidance on synthetic data's legal status as personal data under HIPAA and GDPR are critical determinants of market adoption pace, as healthcare organizations' willingness to rely on synthetic data for regulatory and commercial purposes depends on regulatory clarity about its privacy status.
Rapid Adoption of Generative AI in Healthcare Data Creation
The extraordinary pace of generative AI capability advancement since the widespread adoption of transformer-based large language models and diffusion models from 2022 onward has dramatically expanded the technical frontier of synthetic medical data quality, diversity, and multimodal richness, accelerating commercial adoption by making synthetic data outputs that were previously only achievable by specialist research teams accessible through user-friendly commercial platform interfaces. The progression from early GAN-based synthetic EHR generators, which produced synthetic patient records with reasonable statistical fidelity but visible distributional artifacts detectable by clinical statisticians, to current transformer-based and diffusion-model-based systems capable of generating synthetic medical records, imaging studies, clinical notes, and genomic profiles simultaneously as coherent multimodal patient representations reflects a fundamental leap in generative AI capability that has coincided with the healthcare industry's growing urgency to address its AI training data scarcity.
The broad accessibility of foundation model infrastructure through cloud AI platforms from Google, Microsoft, and Amazon has lowered the technical barrier for synthetic medical data platform companies to build and deploy state-of-the-art generative models without the enormous research and compute investment that frontier model development previously required, enabling a growing ecosystem of specialized synthetic healthcare data companies to offer commercially competitive products. The convergence of improved generative model quality, growing cloud accessibility of model training infrastructure, and maturing commercial demand for synthetic healthcare AI training data is creating a self-reinforcing market development cycle that is expected to sustain strong growth throughout the forecast period.
Emergence of Healthcare Digital Twins and Virtual Patient Models
The expansion of synthetic medical data generation from static dataset production toward dynamic virtual patient modeling — generating computationally simulated patient representations that can respond realistically to clinical interventions, disease progression trajectories, and treatment protocols — represents the most transformative frontier application of synthetic medical data technology. Healthcare digital twins extend the synthetic data concept beyond training data augmentation toward interactive simulation environments where clinical AI algorithms, drug candidates, and care protocols can be tested against populations of virtual patients before deployment in real clinical settings. The pharmaceutical industry's interest in in silico clinical trial simulation, where virtual patient cohorts modeled on synthetic representations of real patient populations are used to predict trial outcomes and optimize protocol design prior to expensive real-world trial execution, represents a high-value near-term application of healthcare digital twin capabilities that several platform vendors including Syntegra and MDClone are actively developing.
The FDA's increasing receptivity to computational modeling and simulation evidence in regulatory submissions, documented in its Digital Health Center of Excellence guidance documents and its ongoing engagement with in silico clinical trial methodologies, is creating a regulatory pathway for pharmaceutical companies to use synthetic patient model outputs as supporting evidence in drug development submissions, representing a potential landmark shift in the regulatory acceptability of synthetic data that would substantially expand the market's commercial scope. The National Institutes of Health's investment in virtual patient modeling research programs and the European Medicines Agency's engagement with the European Virtual Human Twin initiative demonstrate the scientific community's and regulators' recognition of the transformative potential of healthcare digital twin technology.
|
Parameter |
Details |
|
Market Size by 2036 |
USD 2.18 Billion |
|
Market Size in 2026 |
USD 412 Million |
|
Market Size in 2025 |
USD 318 Million |
|
Market Growth Rate (2026–2036) |
CAGR of 18.2% |
|
Dominating Region |
North America |
|
Fastest Growing Region |
Asia-Pacific |
|
Base Year |
2025 |
|
Forecast Period |
2026 to 2036 |
|
Segments Covered |
Data Type, Technology, Deployment Mode, End User, and Region |
|
Regions Covered |
North America, Europe, Asia-Pacific, Latin America, and Middle East & Africa |
Increasing Need for Privacy-Preserving Healthcare Data
The primary structural driver of the synthetic medical data generation platforms market is the irreducible tension between the data intensity requirements of modern healthcare AI development and the strict legal, regulatory, and ethical constraints that govern the collection, storage, and sharing of real patient health information. Healthcare data is the most comprehensively regulated category of personal data in virtually every jurisdiction globally, subject to HIPAA's covered entity obligations and minimum necessary access standards in the United States, GDPR's lawful basis requirements and explicit prohibition of unnecessary processing of special category health data in Europe, and equivalent comprehensive data protection frameworks in Canada, Australia, Japan, South Korea, India, and Brazil. These regulatory frameworks impose substantial compliance costs, liability exposure, and institutional friction on any process that involves accessing, aggregating, or sharing real patient data across organizational boundaries, which is precisely the activity required to assemble the large, diverse, multi-institutional training datasets that clinical AI systems need to achieve generalizable performance.
The de-identification approaches that HIPAA and GDPR permit as mechanisms for reducing privacy obligations on medical data — such as HIPAA's Safe Harbor standard that requires the removal of 18 specific patient identifiers — are increasingly recognized by privacy researchers and regulators as providing inadequate re-identification protection for high-dimensional datasets including genomic sequences, detailed longitudinal clinical records, and medical imaging data, where re-identification attacks using auxiliary publicly available information can successfully match de-identified records to specific individuals. This recognition is creating institutional pressure on healthcare organizations to move beyond conventional de-identification toward formally privacy-preserving synthetic data generation approaches that provide mathematical guarantees against re-identification, regardless of what auxiliary information an adversary might bring to bear. Synthetic data platforms that implement differential privacy at provable privacy budget levels provide this mathematically rigorous privacy guarantee in a way that conventional de-identification cannot.
Growing Demand for AI Training Datasets in Healthcare
The healthcare AI market is experiencing an unprecedented expansion of algorithm development activity across an increasingly broad range of clinical application domains, from established areas including radiology AI for imaging interpretation and clinical decision support for sepsis and deterioration prediction, to emerging applications including AI-assisted drug discovery, genomics-based precision medicine, digital pathology, AI-powered surgical guidance, and ambient clinical intelligence systems that automatically document clinical encounters. Each of these AI application categories requires training datasets of sufficient scale, diversity, and clinical quality to produce algorithms with the performance characteristics necessary for clinical deployment, yet the datasets available to the AI development organizations pursuing these applications are almost invariably insufficient in size, diversity, or label quality relative to what the technical requirements of state-of-the-art deep learning architectures demand.
The AI training data gap in healthcare is particularly acute for rare diseases and underrepresented patient populations, where the small number of patients with specific conditions or the historical underrepresentation of certain demographic groups in electronic health records creates chronic data scarcity for developing algorithms that can reliably serve these populations. Synthetic data generation platforms that can augment rare disease datasets by generating statistically consistent additional patient records, or that can generate synthetic patient representations for demographic groups underrepresented in training data, address a critical AI fairness and generalizability challenge that is receiving growing attention from both AI developers and healthcare regulatory agencies including the FDA and the European Commission's AI Act implementation bodies.
Increasing Use of Synthetic Data for Clinical Trial Simulations
The pharmaceutical industry's application of synthetic patient population modeling to clinical trial design optimization and in silico trial simulation represents one of the highest-value near-term commercial opportunities for synthetic medical data generation platforms. Clinical trials represent the most resource-intensive component of pharmaceutical drug development, with Phase III trials for major indications routinely costing USD 300 million to over USD 1 billion and requiring multi-year enrollment periods that are frequently extended by recruitment challenges, protocol amendments, and interim analysis delays. Synthetic data generation platforms that can produce virtual patient cohorts representative of real patient populations enable pharmaceutical companies to run computational pre-trials that test protocol design assumptions, sample size calculations, endpoint sensitivity analyses, and subgroup effect predictions against synthetic data before committing to expensive real-world trial designs.
The FDA's emerging openness to augmenting clinical trial evidence with real-world evidence and in silico modeling results in regulatory submissions, reflected in its Real-World Evidence Framework and its engagement with adaptive trial design methodologies, is creating a regulatory pathway for pharmaceutical companies to use synthetic patient model outputs as supporting evidence for regulatory decisions. Several pharmaceutical companies including Novartis, AstraZeneca, and Pfizer have publicly engaged with in silico clinical trial modeling programs, and the contract research organization industry is developing synthetic data augmentation capabilities for trial design services that will accelerate pharmaceutical sector adoption through the forecast period.
How Does the EHR Data Segment Lead the Market?
In 2026, the electronic health records (EHR) data segment is expected to hold the largest share of the synthetic medical data generation platforms market. EHR data is the most universally collected, institutionally held, and broadly applicable category of healthcare data for clinical AI development, encompassing patient demographics, diagnoses, procedures, medications, laboratory results, vital signs, and clinical notes that collectively describe the trajectory of a patient's healthcare interactions over time. The AI applications that can be developed from EHR training data span the broadest range of clinical decision support, population health management, risk stratification, and healthcare operations optimization use cases, creating large and diverse commercial demand for synthetic EHR data generation capabilities. The regulatory restrictions on real EHR sharing under HIPAA and GDPR are among the most commercially consequential barriers to EHR-based AI development, making synthetic EHR data generation one of the most commercially motivated applications of the technology.
However, the medical imaging data segment is expected to witness the fastest growth during the forecast period. The radiology AI market is growing at exceptional pace, with the FDA clearing an increasing number of AI-powered imaging analysis algorithms annually, and the training data requirements for state-of-the-art deep learning radiology algorithms substantially exceed what most individual healthcare institutions can provide from their own imaging archives. Diffusion model-based synthetic medical imaging platforms capable of generating radiologically realistic chest radiographs, brain MRI sequences, mammograms, and histopathology slides at scale are providing radiology AI developers with a practical solution to training data scarcity that is driving rapid adoption of synthetic imaging generation platforms.
Why Do GANs Lead the Technology Segment?
In 2026, the generative adversarial networks (GANs) segment is expected to hold the largest share of the synthetic medical data generation platforms market by technology. GANs have served as the foundational generative architecture for synthetic medical data applications since their introduction to healthcare data generation research in the mid-2010s, and the decade of research and commercial development investment in GAN-based medical data synthesis has produced a mature ecosystem of GAN architectures specifically optimized for healthcare data modalities, including Wasserstein GANs and conditional GANs for tabular EHR data, and StyleGAN and progressive growing GAN variants for medical image synthesis. The commercial platform implementations of GAN-based synthetic medical data generation developed by MDClone, Syntegra, Gretel AI, and Mostly AI are built on GAN foundations refined through years of healthcare-specific validation and deployment experience, representing proven and commercially trusted technologies that healthcare enterprise customers have evaluated and adopted.
However, the diffusion models segment is expected to witness the fastest growth during the forecast period. Diffusion models have demonstrated state-of-the-art performance in medical image synthesis tasks that significantly exceed GAN benchmarks in image fidelity, diversity, and controllability, driven by the same technical advances in denoising diffusion probabilistic models and latent diffusion architectures that have powered the consumer image generation revolution. The publication of landmark research demonstrating diffusion model superiority in chest radiograph synthesis, skin lesion image generation, and histopathology slide augmentation has rapidly shifted the preferred generative architecture for medical imaging AI development teams from GAN-based to diffusion-based approaches, creating strong demand growth for platforms offering diffusion model-based synthetic imaging generation capabilities.
How Do Cloud-Based Platforms Lead the Market?
In 2026, the cloud-based platforms segment is expected to hold the largest share of the synthetic medical data generation platforms market by deployment mode. Cloud deployment provides access to the large-scale GPU compute resources required for training and running state-of-the-art generative models without requiring healthcare organizations to make substantial capital investments in on-premise GPU infrastructure, and offers the scalability to generate synthetic datasets of varying sizes on-demand without provisioning peak capacity hardware. Cloud-based synthetic data platforms are particularly well-suited to the large pharmaceutical company and AI developer customer segments, which have established cloud data and AI infrastructure and are accustomed to procuring AI capabilities as cloud services. The subscription pricing models enabled by cloud deployment align with enterprise software procurement preferences and allow platform vendors to grow revenue proportionally with customer synthetic data generation volume.
However, the on-premise platforms segment maintains an important market position for healthcare providers and certain highly regulated pharmaceutical and government healthcare customers where organizational data governance policies prohibit uploading patient-derived training data to cloud environments outside the institutional security perimeter, even for the purpose of training synthetic data generation models. Hybrid deployment models, which allow the sensitive model training phase to occur within the institutional security perimeter while enabling synthetic data generation and distribution through cloud services, are expected to grow as platform vendors develop architectures that accommodate the security requirements of the most risk-averse enterprise healthcare customers while enabling the operational flexibility of cloud-based synthetic data distribution.
Why Do Pharmaceutical and Biotechnology Companies Lead the End User Market?
In 2026, the pharmaceutical and biotechnology companies segment is expected to hold the largest share of the synthetic medical data generation platforms market by end user. Pharmaceutical companies are the largest and most sophisticated consumers of external healthcare data services globally, with established infrastructure for real-world evidence data procurement, biostatistical data analysis, and clinical informatics that provides organizational context for integrating synthetic data generation capabilities alongside existing real-world data workflows. The scale and commercial value of pharmaceutical companies' clinical data needs — spanning drug safety signal detection across large patient populations, clinical trial cohort identification and protocol optimization, post-market surveillance obligations, and payer evidence package development — justify the investment in premium synthetic data platform capabilities that smaller healthcare organizations and research groups cannot easily rationalize.
However, the AI and digital health companies segment is expected to witness the fastest growth during the forecast period. The proliferation of healthcare AI startups, digital therapeutics companies, medical device software developers, and health technology platforms developing AI-powered clinical products has created a large and rapidly expanding community of organizations with urgent synthetic data needs and no practical alternative access to the real patient datasets they require for AI model development. Unlike established pharmaceutical companies or hospital systems, these organizations typically lack institutional data access agreements, clinical informatics expertise, or IRB-approved research infrastructure that would enable them to work directly with real patient data, making commercially available synthetic data generation platforms their primary or only practical option for obtaining healthcare AI training data.
How is North America Maintaining Market Leadership?
In 2026, North America is expected to hold the largest share of the global synthetic medical data generation platforms market. The United States is the primary driver of North American market leadership, reflecting the country's dominant position in global healthcare AI development activity, the strong commercial incentive for synthetic data adoption created by HIPAA's restrictive patient data sharing framework, and the substantial venture capital ecosystem supporting healthcare data infrastructure and healthcare AI companies. The United States hosts the headquarters or primary operations of the majority of commercial synthetic data platform vendors including MDClone, Syntegra, Gretel AI, Tonic.ai, and HealthVerity, as well as the Google Health and Microsoft healthcare AI divisions that are integrating synthetic data capabilities into major technology platform offerings.
The U.S. healthcare system's advanced electronic health record adoption, with near-universal EHR deployment across hospitals and a rapidly growing proportion of outpatient settings, has created the large digitized patient data assets from which synthetic data generation models can be trained, and has also created the regulatory compliance pressures that motivate synthetic data adoption as an alternative to direct data sharing. The FDA's active Digital Health Center of Excellence program and its evolving guidance on AI/ML-based SaMD create a regulatory context that is progressively clarifying the potential role of synthetic data in clinical AI regulatory submissions, further supporting North American market development. Canada contributes to regional leadership through its strong academic health system research infrastructure, the Canadian Institute for Health Information's synthetic data exploration programs, and the growing ecosystem of Canadian health AI companies requiring synthetic training data.
Which Factors Drive Asia-Pacific's Rapid Growth?
Asia-Pacific is expected to witness the highest growth rate in the synthetic medical data generation platforms market during the forecast period. China's national artificial intelligence and digital health investment programs, which have established healthcare AI as a strategic priority under the New Generation AI Development Plan and the Healthy China 2030 initiative, are creating large-scale demand for healthcare AI development that is generating growing recognition of synthetic data's role in enabling AI development at scale without compromising patient privacy under China's Personal Information Protection Law (PIPL) and Data Security Law frameworks that impose stringent controls on healthcare data cross-border transfer and institutional sharing.
Japan's advanced healthcare digitization infrastructure, including its My Number health record platform and the AMED's national research database programs, is creating a well-organized institutional healthcare data ecosystem that is generating both the data assets from which synthetic data generation models can be trained and the privacy compliance requirements that motivate synthetic data adoption. Japan's pharmaceutical industry, which includes globally significant companies including Takeda, Astellas, and Daiichi Sankyo with active real-world evidence and clinical AI programs, represents an important Asia-Pacific customer segment for synthetic medical data platforms. India's health technology sector, which encompasses a growing ecosystem of digital health companies, clinical research organizations, and AI startups serving both domestic and global pharmaceutical clients, is developing rapidly as a synthetic data adoption market driven by the increasing recognition among Indian health AI developers that synthetic data offers a privacy-compliant pathway to the large medical training datasets their international market ambitions require. Singapore's position as Asia-Pacific's leading health technology hub, supported by the Ministry of Health's Synapxe health data platform and its strong academic-industry collaboration infrastructure, makes it a disproportionately influential synthetic data adoption market relative to its population size.
Some of the key companies operating in the global synthetic medical data generation platforms market are MDClone, Synthea (MITRE), Gretel AI, Mostly AI, Hazy (Hazy Ltd.), Replica Analytics (AELIX Therapeutics), Syntegra, Datomize, YData, Betterdata, Tonic.ai, HealthVerity, IQVIA, Google Health, and Microsoft.
The global synthetic medical data generation platforms market is expected to grow from USD 412 million in 2026 to USD 2.18 billion by 2036.
The global synthetic medical data generation platforms market is projected to grow at a CAGR of 18.2% from 2026 to 2036.
The electronic health records (EHR) data segment is expected to dominate the overall market in 2026, reflecting EHR data's position as the most universally collected and broadly applicable healthcare data type for clinical AI development. The medical imaging data segment is expected to witness the fastest CAGR, driven by the explosive growth of radiology AI development, the enormous scale of labeled imaging data required for deep learning model training, and the demonstrated ability of diffusion model-based synthetic imaging platforms to generate clinically realistic artificial imaging studies that improve AI model training outcomes.
The generative adversarial networks (GANs) segment is expected to dominate the overall market in 2026, reflecting GANs' established position as the foundational generative architecture across commercial synthetic medical data platform deployments. The diffusion models segment is expected to witness the fastest CAGR, driven by diffusion models' demonstrated state-of-the-art performance in medical image synthesis and the rapid adoption of diffusion model-based synthetic imaging platforms by radiology AI development teams.
The cloud-based platforms segment is expected to dominate the overall market in 2026 and maintain the fastest growth trajectory, reflecting cloud deployment's advantages in compute scalability, subscription pricing alignment with enterprise procurement preferences, and accessibility for the AI developer and digital health company customer segments that lack on-premise GPU infrastructure.
The pharmaceutical and biotechnology companies segment is expected to dominate the overall market in 2026, reflecting the pharmaceutical industry's large-scale real-world evidence data needs and established healthcare data platform procurement infrastructure. The AI and digital health companies segment is expected to witness the fastest CAGR, driven by the rapid proliferation of healthcare AI startups and digital health companies that require synthetic medical training data but lack direct access to real patient datasets.
North America is expected to lead the global market in 2026, supported by the United States' dominant position in healthcare AI development, HIPAA-driven synthetic data adoption incentives, and the concentration of leading platform vendors. Asia-Pacific is expected to witness the fastest CAGR, driven by China's national healthcare AI investment programs, Japan's pharmaceutical industry real-world evidence adoption, and India's and Singapore's rapidly growing health technology ecosystems.
The major players are MDClone, Synthea (MITRE), Gretel AI, Mostly AI, Hazy (Hazy Ltd.), Replica Analytics (AELIX Therapeutics), Syntegra, Datomize, YData, Betterdata, Tonic.ai, HealthVerity, IQVIA, Google Health, and Microsoft.
























Published Date: Mar-2026
Published Date: Aug-2024
Please enter your corporate email id here to view sample report.
Subscribe to get the latest industry updates